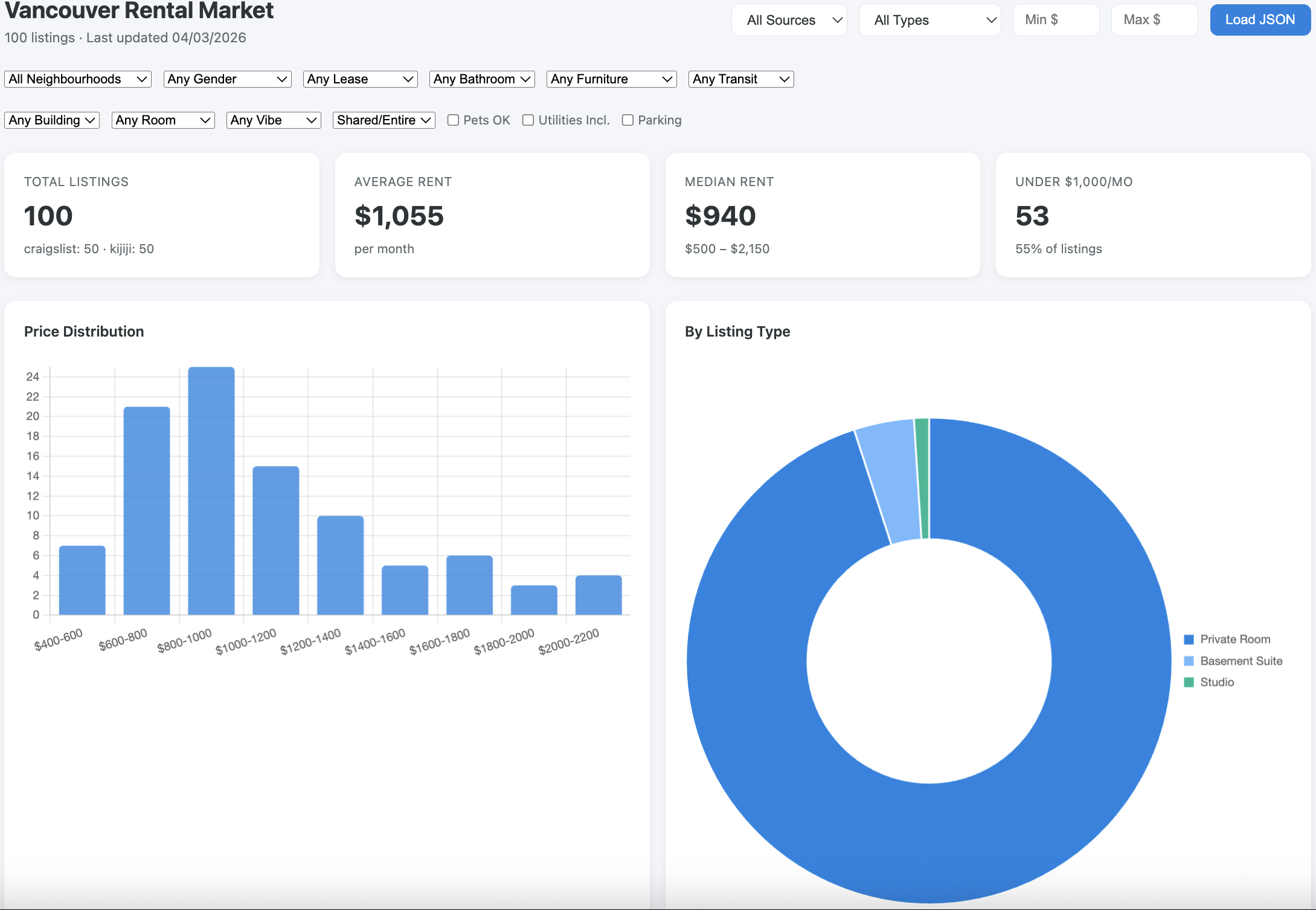
Overview
Vancouver Rental Scraper is a Python tool that pulls rental listings from multiple sources — Craigslist, Kijiji, and Facebook housing groups — and normalises them into a single, consistent format. The goal is to give renters a clearer picture of what's available and at what price, without having to manually trawl through three different platforms.
The Problem
Finding a rental in Vancouver means checking Craigslist, Kijiji, and Facebook separately, each with different layouts, search tools, and listing formats. It's time-consuming, and it's hard to compare prices across sources or spot when something's a good deal. There's no easy way to get a unified view of the market without doing it all by hand.
The Solution
The scraper runs three purpose-built modules — one per source — that each handle the quirks of their respective platform. Craigslist and Kijiji are scraped via Playwright browser automation, while Facebook uses Chrome DevTools Protocol to attach to an existing logged-in session. All three produce identical Listing objects with price, location, listing type, amenities, dates, and source tracking, making cross-platform comparison straightforward.
For Facebook, where listings are unstructured posts rather than form-filled data, the scraper uses Claude's API to extract structured information from free-text descriptions — parsing out prices, bedroom counts, and locations from conversational posts.
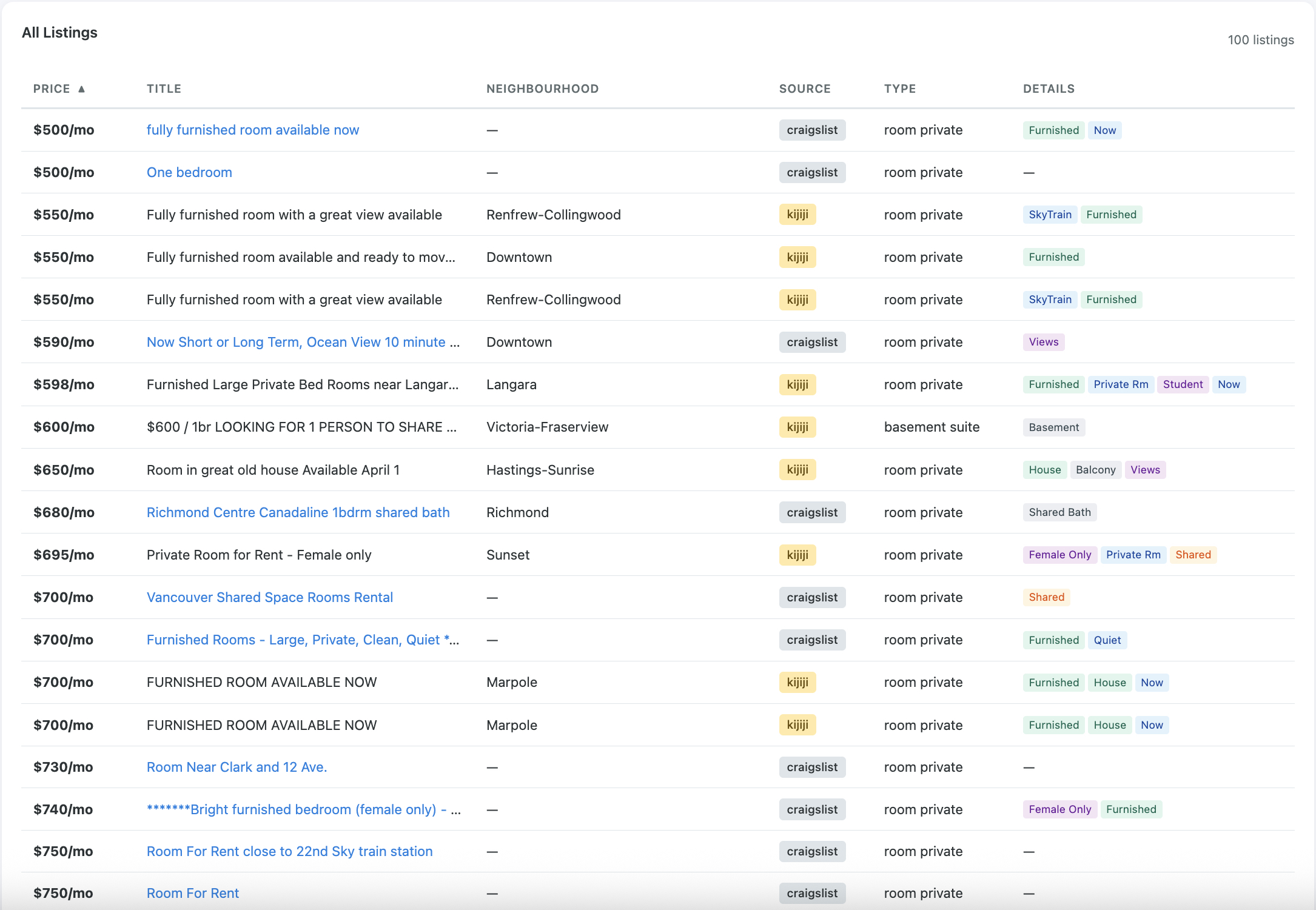
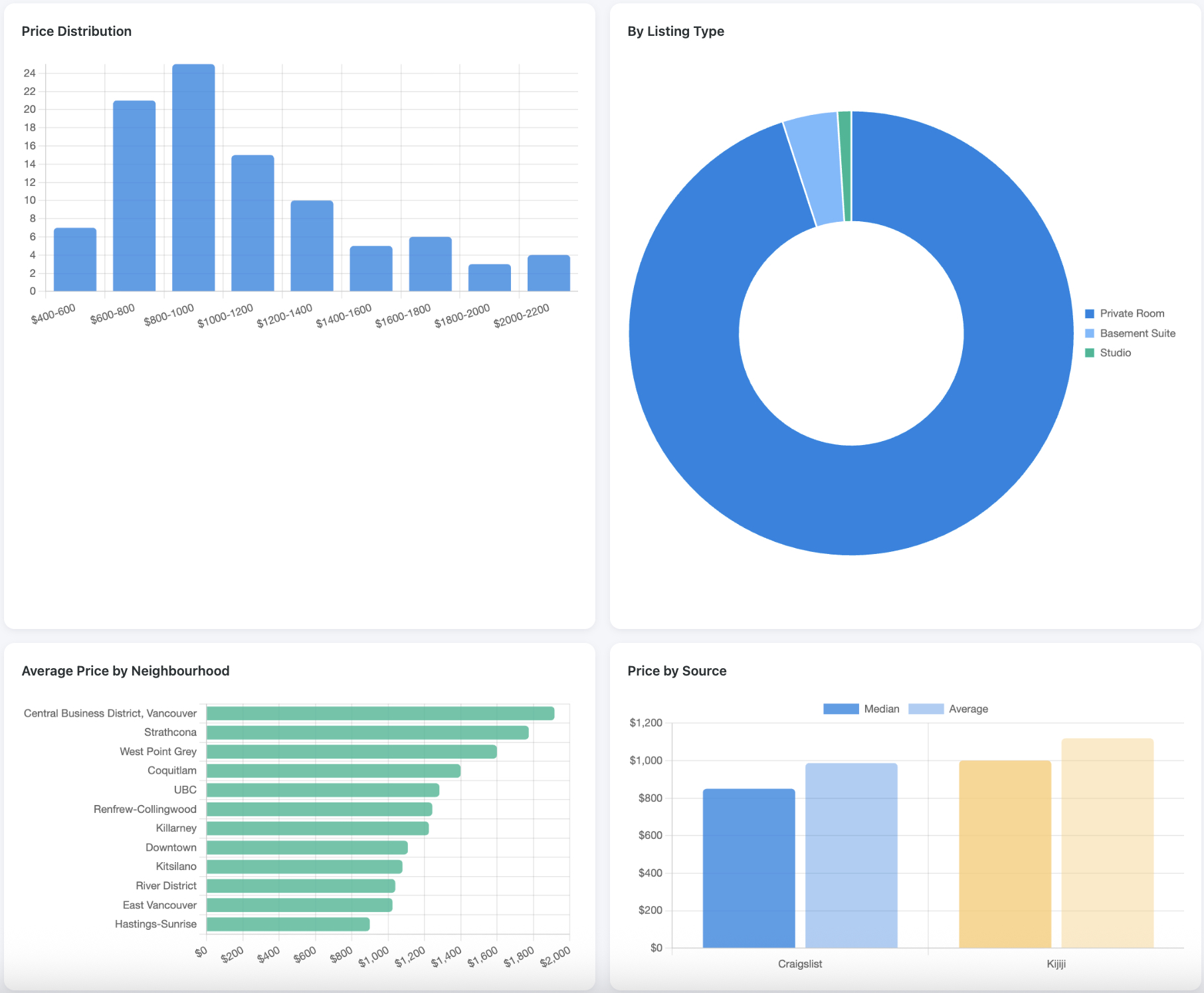
How It's Built
The core is Python with Playwright for browser automation and BeautifulSoup4 for HTML parsing. Each scraper module sits in src/rental_scraper/scrapers/ and implements the same interface, making it easy to add new sources later. The unified data model lives in models.py — a dataclass that all scrapers must conform to.
Facebook extraction is the most interesting piece technically. Since Facebook housing group posts don't follow a consistent template, the scraper attaches to Chrome via DevTools Protocol, scrolls through group posts, and sends the raw text to Claude's API via the Anthropic SDK. Claude parses out structured listing data from natural language — handling everything from "$2,200/mo 1BR in Kitsilano" to paragraph-length descriptions.
The project uses httpx for async HTTP operations and python-dateutil for normalising the various date formats across platforms. Docker and Google Cloud Build handle deployment for scheduled runs.
Challenges & Learnings
The biggest challenge was dealing with three fundamentally different data sources. Craigslist has clean, structured HTML. Kijiji is somewhere in the middle. Facebook is completely unstructured free text — and requires authentication, which means you can't just fire up a headless browser and go. The Chrome DevTools Protocol approach for Facebook was a pragmatic workaround: attach to an already-authenticated browser session rather than trying to automate login.
Using Claude for data extraction from Facebook posts was a learning experience in prompt engineering for structured output. Getting consistent, reliable parsing from messy real-world text required careful prompt design and validation of the returned data against the expected schema.
What's Next
The roadmap includes cross-source deduplication (the same listing often appears on multiple platforms), SQLite-backed historical tracking to spot pricing trends over time, comparative filtering for side-by-side analysis, and markdown report generation aimed at giving renters concrete data to negotiate with.